
The 2025 Beijing Junior High School Entrance Examination has concluded, with 110,500 students successfully completing their tests. This year marks a significant shift, not just for the students, but potentially for the future of education itself, as it’s the first iteration of Beijing’s new middle school exam reforms. The examination period has been compressed from three days to two, and the total score has been reduced from 670 to 510 points. Perhaps the most notable change is the adoption of an open-book format for “Morality and Law” (道德与法治).
This reduction in scoring means each point carries more weight, potentially intensifying competition at the higher end of the score spectrum. Furthermore, the exam design across subjects is leaning towards assessing students’ core competencies and critical thinking skills.
For instance, the mathematics section saw a decrease in the proportion of simpler questions, featuring more innovative problem types. The introduction of new functions and complex comprehensive geometry problems aimed to enhance differentiation among students. The Chinese language exam, on the other hand, emphasized fundamental language proficiency and students’ ability to interpret and apply language within contextual scenarios.
The student feedback has been stark: the exam was, by many accounts, incredibly challenging.
Take the Chinese essay, for example. Students had to choose between two prompts: “Living This Way is Healthier” focusing on science and well-being, or “A Science Class,” emphasizing scientific literacy in practical life. While the topics might seem straightforward, crafting a standout essay proved to be a significant hurdle, leading many students to exclaim, “I know this topic, but it’s so hard to write about!”
This begs a fascinating question: if we were to put today’s leading AI large language models into the shoes of these 2025 Beijing junior high exam candidates, how would they fare?
We were particularly curious to see if these sophisticated AI models, often lauded for their capabilities, could truly perform as academic prodigies when measured against a standardized benchmark for junior high academic achievement.
Seven Leading Large Language Models Take on the 2025 Beijing Junior High Exam: A Real-World Performance Test
Let’s introduce our AI test-takers and the methodology employed.
The Subjects:
The 2025 Beijing Junior High Entrance Examination, specifically the Chinese essay (Prompt 2), English essay (Prompt 2), and the entire mathematics paper.
The AI Candidates:
DeepSeek, ByteDance Doubao, iFlytek Spark, Tongyi Qianwen, Tencent Hunyuan, Baidu Wenxin Yiyan, and GPT.
This selection represents the most commonly used and representative AI models available. Less common or non-representative models were excluded from this evaluation.
The Testing Methodology:
To ensure a fair assessment, all participating AI models had their internet connectivity disabled, and their advanced reasoning capabilities were enabled. The essays were submitted in a text format. Scoring for the Chinese essay was conducted by Li Hao, a distinguished Chinese language teacher from Renmin University High School Affiliated School and a senior researcher in junior high exam design, alongside Jin Yujia, a veteran Chinese language research expert and invited lecturer who has contributed to exam preparation strategies for several key middle schools. Both experts graded independently, and their average scores were used for the final evaluation.
For the English essay, scoring was performed by Zhang Yang, former junior high exam designer and English discipline lead for Xianning City, and Shi Yang, an English education researcher with over 10 years of experience and a frequent scorer for the Beijing Junior High English exam. Their average scores were also used.
Mathematics questions were presented through image scanning and LaTeX formatting. Scoring adhered to the same standards as human candidates: objective questions (multiple-choice and fill-in-the-blanks) were graded solely on the final answer, irrespective of the model’s reasoning process. For subjective questions (problem-solving and proofs), a methodology of awarding points based on correctness of the final answer for standard problems and step-by-step scoring for proof-based questions was applied.
Let’s delve into the final scores for these seven AI models across the three subjects:

For this evaluation, we opted for Prompt 2 in both the Chinese and English essay sections.

The 2025 Beijing Junior High Chinese essay, with a maximum score of 40 points, required students to choose one of two prompts. Essays needed to be positively themed and between 600-800 characters.
Prompt 2, “A Science Class,” was chosen as it played more directly to the AI’s strengths, allowing for a better assessment of their analytical and reasoning capabilities compared to the more life-experience-based prompt.

The English essay, carrying a maximum of 10 points, also presented students with a choice of two prompts, requiring them to write a paragraph of at least 50 words.
Prompt 1 for the English essay included a chart, which would have tested OCR capabilities. However, the varying OCR technologies across different AI models made standardization difficult. Therefore, Prompt 2, which did not involve visual data, was selected to ensure a level playing field.
The mathematics portion, with its algebraic formulas, complex equations, and graphical elements, heavily tested the AI’s ability to analyze and extract information from documents. This section was administered through two input methods: image scanning and LaTeX format.
Let’s break down the individual subject scores:
I. Mathematics:

Summary: In the mathematics test, when presented via image format, iFlytek Spark, Doubao, and GPT secured the top three positions with scores exceeding 85 points. Tongyi Qianwen, Wenxin Yiyan, and DeepSeek followed, scoring 73, 68, and 63 points, respectively. These scores are considerable, especially given students commonly reported the exam’s heavy reliance on text and time constraints. Notably, DeepSeek was effectively eliminated from the image format test due to significant issues with recognizing mathematical expressions, leading to its lowest score.
For objective questions like multiple-choice and fill-in-the-blanks, performance was fairly consistent among most models, with scores ranging from 14-16 points, except for DeepSeek in fill-in-the-blanks which achieved a perfect score. iFlytek Spark X1 achieved full marks in both categories, while Tongyi Qianwen and Wenxin Yiyan, despite lower overall scores, demonstrated strength in fill-in-the-blanks, also scoring perfectly.
The primary differentiator between the models emerged in the subjective problem-solving sections. DeepSeek, for instance, only managed 39 out of a possible 68 points in these sections, a stark 20-point difference compared to Doubao’s 59 points.
The models generally performed well in algebraic manipulation, solving systems of inequalities, simplifying rational expressions, applying equations, and function-related problems, achieving high accuracy rates.
However, challenges arose with questions involving image interpretation, such as geometric proofs, statistical charts, and function graphs where models frequently lost points. This is attributed to difficulties in accurately identifying graphical elements or interpreting visual cues, particularly in geometry problems requiring spatial reasoning or dynamic analysis.
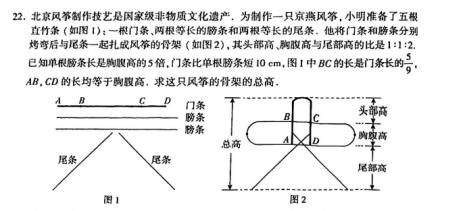

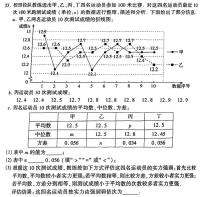
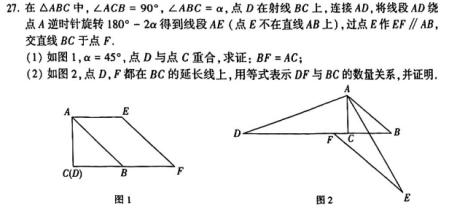

When input via LaTeX, most models, excluding GPT, showed comparable scores, ranging from 78 to 89 points. iFlytek Spark, DeepSeek, and Tencent Hunyuan led in this format, while Baidu Wenxin Yiyan and GPT lagged. It’s worth noting that the GPT-o3 version tested experienced issues with missing images in LaTeX, leading to incorrect answers and significantly lower scores (dropping from 86 to 63). Conversely, DeepSeek’s performance improved dramatically in LaTeX, correctly interpreting the mathematical expressions and boosting its score to 84. The remaining five models demonstrated consistent performance across both image and LaTeX formats, indicating areas for future optimization.
II. Chinese Essay:

Summary: In the Chinese essay evaluation, the lowest score among the seven AI models was 32.5, with the highest reaching 37.5, translating to approximately 81-94% on a percentage scale, with an average close to 86%. The models demonstrated strong “finished product” delivery capabilities, accurately interpreting writing instructions and producing logically coherent, topic-focused content that avoided basic errors like deviation from the prompt. They also incorporated simulated human-like perspectives, reducing the mechanical feel often associated with AI output.
However, subtle differences emerged in stylistic refinement. Overseas models like GPT, despite robust language processing, showed room for improvement in adapting to the Chinese context. While their essays were well-structured and fluent, they sometimes lacked depth in theme, felt detached from reality, or contained repetitive passages. Chinese models like Tencent Hunyuan, Baidu Wenxin Yiyan, and Tongyi Qianwen successfully adhered to the “Science Class” theme but exhibited superficial emotional expression and generic analogies. Their writing, while competent, was assessed as solid mid-to-upper tier performance.
ByteDance Doubao and DeepSeek showcased more impressive creative output, achieving high-tier scores and nearing mastery. iFlytek Spark claimed the top spot with a score of 37.5, lauded by experts for its profound insights, vivid language, and a seamless integration of scientific observation and emotional depth, marking it as an exceptional piece of writing.
Here’s a glimpse into the essay generation process for each model:
iFlytek Spark:

DeepSeek:

Doubao:

Tongyi Qianwen:

Baidu Wenxin Yiyan:

GPT:

Tencent Hunyuan:

III. English Essay:

Summary: The English essay scores ranged from a low of 7 to a perfect 10, equating to 70-100% with an average score above 84%. While impressive, this slightly trails the Chinese essay performance, suggesting that most domestic AI models excel more in Chinese writing. The 3-point score gap indicates significant variability, with some models appearing to have specific weaknesses.
Tencent Hunyuan’s essay was rated as “good,” with complete structure and clear meaning, but lacked unique details and sophisticated sentence structures, making it somewhat monotonous. Further diversification and advancement in sentence complexity could elevate it. Surprisingly, GPT, despite its native English advantage, scored only 7.5. While it covered all points and maintained clarity, its arguments were simplistic, and sentence structures predominantly featured basic constructions, lacking complexity.
DeepSeek, while using idiomatic expressions and showing potential, exhibited a logical gap between its envisioned scenario and the outlined reasons, hindering a cohesive narrative.
In contrast, Tongyi Qianwen and Baidu Wenxin Yiyan both scored 9. Wenxin Yiyan received a “distinguished” rating, while Tongyi Qianwen was marked as “good.” Both models covered all required points but had minor flaws; Tongyi Qianwen suffered from unclear paragraphing and logical flow, whereas Wenxin Yiyan’s complex sentence structures might be challenging for junior high students. However, Wenxin Yiyan’s imperfections were deemed less critical.
Doubao presented a similar issue, with vocabulary and phrasing exceeding the typical junior high level, making it less universally applicable as a model essay. Despite scoring 8.5 and earning a “distinguished” rating, the score itself was not the sole determinant for categorization.
iFlytek Spark achieved a perfect 10 in the English essay, earning high praise from the evaluators for fully addressing the prompt’s requirements. It offered a vivid vision of future libraries and articulated their functions with rich detail, exhibiting perfect structure and language expression.
Here’s a look at the generated English essays:
iFlytek Spark:

DeepSeek:

Doubao:

Tongyi Qianwen:

Baidu Wenxin Yiyan:

GPT:

Tencent Hunyuan:

Conclusion:
As AI models narrated “science classes” through essays and crafted practical advice in English, while also tackling complex mathematical derivations, we witnessed not just an evolution of code and algorithms but humanity’s ongoing quest to push the boundaries of intelligence. The near-perfect essays and rigorous mathematical reasoning demonstrate that AI models are far beyond mere text manipulators; they are learning, growing at an astonishing pace, and becoming increasingly reliable digital companions.
This also underscores the crucial need for students to shift from rote memorization and mechanical problem-solving towards active comprehension, critical thinking, and inquiry-based learning, fostering interdisciplinary understanding and flexible application of knowledge.
However, it’s essential to remember that even the most advanced algorithms cannot fully replicate the nervous anticipation of a student in an exam hall, nor can they capture the spark of human ingenuity. The AI’s high-scoring performance is, in essence, an invitation—an invitation to reassess the very meaning of learning and to safeguard our capacity for independent thought amidst the technological revolution.
Looking ahead, humans and AI may well become collaborators, leveraging their respective strengths to co-create even more remarkable achievements. This junior high examination isn’t an endpoint, but rather a new beginning as we navigate the era of intelligence hand-in-hand with AI.
Original article, Author: Tobias. If you wish to reprint this article, please indicate the source:https://aicnbc.com/4040.html