
When it comes to the most talked-about models in recent times, the Mixture of Experts (MoE) architecture undoubtedly tops the list.
Its brilliance lies in its ability to delegate tasks to specialized expert networks, enhancing overall system performance. However, there’s a catch.
Ironically, the very component that makes MoE so effective—its expert networks—can also become a bottleneck for inference efficiency.
Under heavy workloads, particularly at scale, MoE doesn’t distribute tasks evenly. Instead, the imbalance in expert network utilization becomes a critical issue.


The root of the problem lies in the uneven distribution of task assignments. Some expert networks are frequently called upon (hot experts), while others remain underutilized (cold experts).
Yes, MoE’s “experts” can be categorized by their workload intensity—and the gap in their utilization can span an order of magnitude.
This imbalance leads to extended inference times, inefficient resource usage, and overall system performance degradation.
So, how can this challenge be addressed?
Huawei has developed a solution that reduces theoretical inference latency by approximately 10% and improves throughput by a similar margin in DeepSeek-V3. The company is also preparing to open-source this solution soon. Let’s dive into the details.
Huawei’s Key Innovation: OmniPlacement
To tackle the imbalance between hot and cold experts, Huawei introduced OmniPlacement, a multi-faceted optimization framework.
In essence, it works by improving MoE inference performance through expert reordering, inter-layer redundancy allocation, and near-real-time dynamic scheduling.
The approach consists of three key steps:
Step 1: Computation-Aware Joint Optimization
Huawei’s team first identified hot and cold experts by analyzing activation patterns. They then applied OmniPlacement, a joint optimization algorithm that balances computational load by considering expert invocation frequency and processing requirements.
Key features of the algorithm include:
- Dynamic priority adjustment: Real-time tracking of expert usage to allocate high-frequency experts to more powerful nodes.
- Communication optimization: Reducing cross-node latency by analyzing activation patterns.
- Layer-specific deployment: Allowing different layers to adopt customized expert allocation strategies.
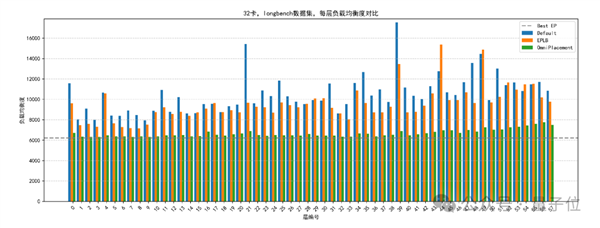
Step 2: Inter-Layer Redundancy for Hot Experts
To alleviate pressure on frequently used experts, Huawei implemented a redundancy strategy that assigns additional instances to high-demand experts, reducing cross-node communication overhead.
This strategy includes:
- Dynamic resource allocation based on real-time demand.
- Layer-specific redundancy configurations.
- Predictive resource assignment to minimize performance gaps.
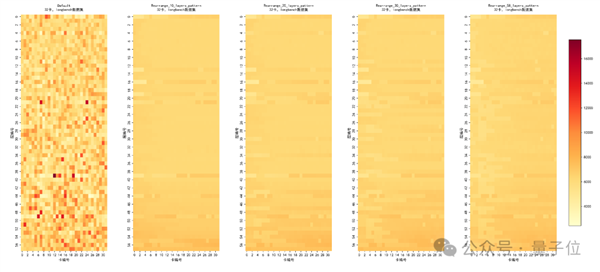
Step 3: Near-Real-Time Scheduling and Dynamic Monitoring
To ensure adaptability, Huawei developed a dynamic scheduling system that operates with minimal latency. This includes:
- Millisecond-level task allocation adjustments.
- Real-time monitoring of expert utilization.
- Dynamic weight adjustment and placement optimization.
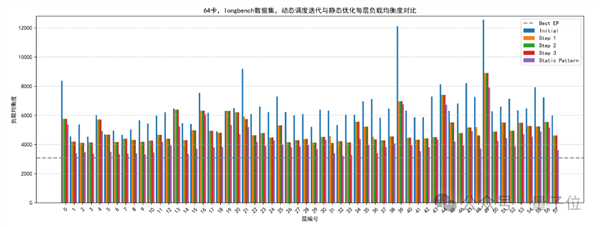
To support these optimizations, Huawei built OmniPlacement, a framework for vLLM inference with the following characteristics:
- High compatibility with existing MoE models.
- Low-latency processing.
- Modular design for easy customization.
- Scalability for future MoE architectures.
DeepSeek V3: A 10% Reduction in System Latency
Huawei tested the framework on DeepSeek-V3 under high-concurrency scenarios, achieving the following results:
- 10% reduction in inference latency.
- 10% improvement in throughput.
- Enhanced system stability under dynamic workloads.
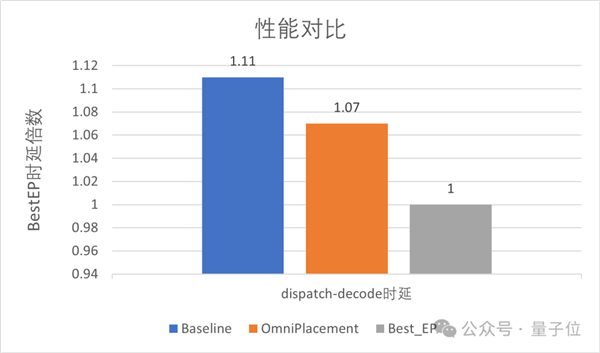
Further analysis shows that OmniPlacement adapts well to different MoE configurations and input distributions, making it a robust solution for large-scale MoE deployment.
Huawei is set to open-source this solution soon, providing the AI community with a powerful tool for optimizing MoE inference.
Technical Report: Download
Technical Blog: Read
Original article, Author: Tobias. If you wish to reprint this article, please indicate the source:https://aicnbc.com/509.html