
The AI speech transcription landscape is bracing for disruption as Alibaba’s Qwen team unveils its latest innovation: the Qwen3-ASR-Flash model. This new offering promises to raise the bar for accuracy and functionality in speech-to-text technology, potentially reshaping how businesses and individuals leverage AI for transcription.
Built upon the foundation of the Qwen3-Omni intelligence and trained on a massive dataset encompassing tens of millions of hours of speech, Qwen3-ASR-Flash is designed for high performance in challenging acoustic environments and with diverse language patterns. This extensive training allows it to discern subtle nuances in speech, setting it apart from earlier generation models.
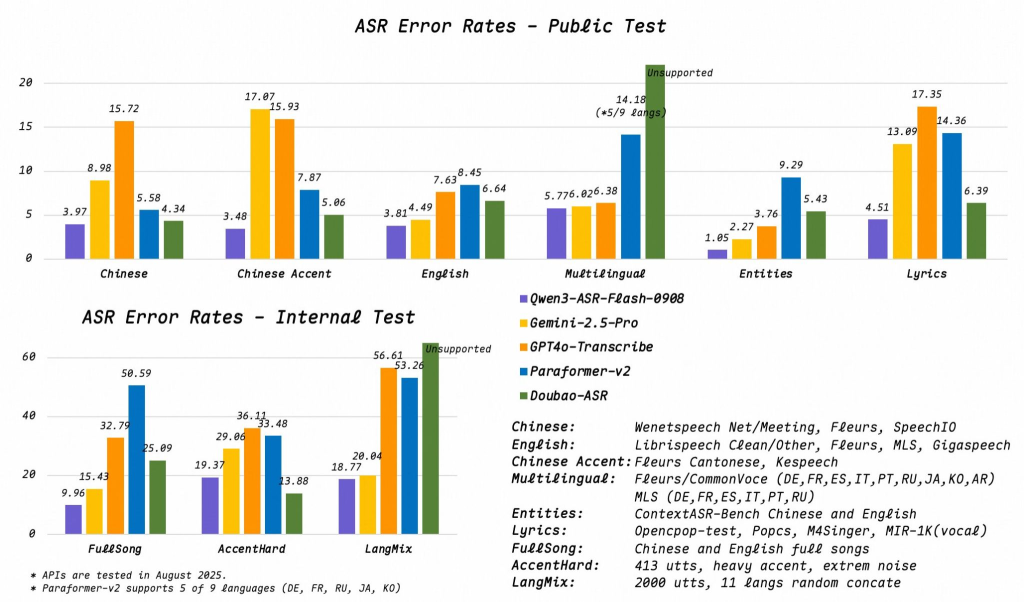
Performance data from tests conducted in August 2025 reveal compelling results, indicating a significant leap in accuracy. According to these internal metrics, Qwen3-ASR-Flash demonstrated a lower error rate than leading competitors in several key areas.
In standard Chinese, Qwen3-ASR-Flash achieved an error rate of just 3.97 percent, outperforming alternatives such as Gemini-2.5-Pro (8.98%) and GPT4o-Transcribe (15.72%). These results point to the model’s advanced capabilities in processing the intricacies of the Chinese language.
The model also showcases proficiency in handling regional Chinese accents, achieving an error rate of 3.48 percent. In English, the model scored a competitive 3.81 percent, again surpassing Gemini (7.63 percent) and GPT4o (8.45 percent). This suggests the model may be tapping in novel techniques for speech recognition.
However, Qwen3-ASR-Flash truly distinguishes itself in the notoriously difficult task of transcribing music. The model exhibits a remarkable ability to decipher lyrics from songs.
In tests involving song lyric recognition, Qwen3-ASR-Flash achieved an error rate of just 4.51 percent, significantly outperforming its rivals. Further internal tests on complete songs yielded an error rate of 9.96 percent, a notable improvement compared to Gemini-2.5-Pro (32.79 percent) and GPT4o-Transcribe (58.59 percent). This capability could open up new possibilities for AI in the music industry, including automated lyric generation, music analysis, and copyright enforcement.

Beyond its accuracy, Qwen3-ASR-Flash introduces a crucial feature: flexible contextual biasing. This innovation represents a significant departure from traditional approaches to transcription customization.
Instead of relying on pre-formatted keyword lists, users can input background text in various formats to tailor the model’s output. This input can range from simple keyword lists to entire documents, or even a combination of both.
This innovative approach eliminates the need for complex preprocessing of contextual information. The model is able to leverage the context to improve its accuracy, while maintaining general performance even when provided with irrelevant text.
Alibaba’s ambition for Qwen3-ASR-Flash is to establish it as a global speech transcription tool. The service offers transcription in 11 languages, accommodating regional dialects and accents from a single model.
Notably, the model provides comprehensive support for the Chinese language, covering Mandarin and major dialects like Cantonese, Sichuanese, Minnan (Hokkien), and Wu.
For English speakers, the model recognizes British, American, and other regional accents. Supported languages also include French, German, Spanish, Italian, Portuguese, Russian, Japanese, Korean, and Arabic.
To further enhance its functionality, Qwen3-ASR-Flash can distinguish between these 11 languages and filter out non-speech segments such as silence and background noise, resulting in cleaner and more accurate output compared to existing AI speech transcription tools.
Original article, Author: Samuel Thompson. If you wish to reprint this article, please indicate the source:https://aicnbc.com/8903.html