
CNBC AI News – June 17, 2025
Moonshot AI has just unveiled Kimi-Dev-72B, a new open-source code large language model (LLM) specifically designed for software engineering tasks, setting a new benchmark in the competitive AI landscape.
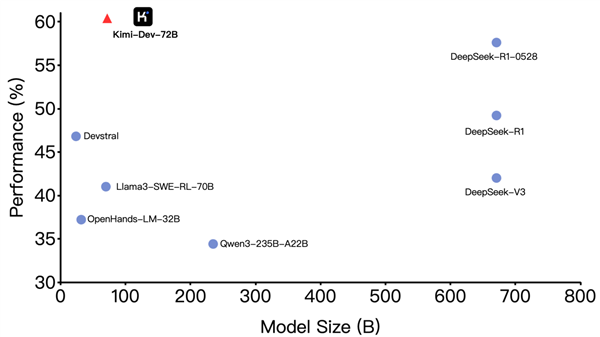
The model has claimed the top spot among open-source models in the SWE-bench Verified programming benchmark. Notably, Kimi-Dev-72B achieved this feat with a parameter size of 72 billion, outperforming the recently released DeepSeek-R1, which boasts a significantly larger 671 billion parameters.

The model leverages reinforcement learning from human feedback (RLHF) to autonomously repair real-world repositories within Docker. This approach ensures the correctness and robustness of its solutions, as rewards are only granted when the entire test suite passes.
The design of Kimi-Dev-72B is built upon several key technical pillars, including the BugFixer and TestWriter combination, mid-stage training, reinforcement learning, and test-time self-play.

The complementary roles of BugFixer and TestWriter form the core of its capabilities, excelling at both error correction and test case generation.
Mid-stage training, using approximately 150 billion high-quality, real-world data points, enhances the model’s understanding of practical bug fixes and unit testing.
Kimi-Dev-72B is now available for download and deployment on Hugging Face and GitHub, with model weights, source code, and other resources readily accessible.

Original article, Author: Tobias. If you wish to reprint this article, please indicate the source:https://aicnbc.com/2684.html