
Rising San Francisco-based AI startup Deep Cogito has made waves in the competitive large language model (LLM) landscape with the introduction of a new family of open-source models, ranging from 3 billion to 70 billion parameters, which the company claims surpass industry titans like Meta’s Llama series, DeepSeek, and Alibaba’s Qwen in performance metrics. The announcement frames the release as a pivotal stride toward the development of general superintelligence—a term that has long hovered at the frontier of speculative AI research.
Deep Cogito positions itself as a challenger in a field dominated by deep-pocketed incumbents, emphasizing that its models demonstrate superior accuracy across multiple benchmarks, such as MMLU and GSM8K, while requiring fewer resources to train. “These models aren’t just incremental upgrades; they’re a reimagining of what scalability in AI can achieve,” a company spokesperson asserted.
Beyond raw numbers lies the company’s core innovation: Iterated Distillation and Amplification (IDA), a training methodology designed to break free from the constraints of traditional model oversight. Unlike conventional approaches that rely on human feedback or larger pre-trained models to guide improvements—which inherently limit teachability—IDA creates a cyclical process where models “think at scale” through computational expansion, then condense those insights into their architecture, fostering exponential growth in capability over time.
Iterated Distillation and Amplification (IDA): The Engine of Self-Improvement
According to Deep Cogito’s research, IDA merges two critical principles seen in breakthrough systems such as AlphaGo: advanced reasoning and iterative self-refinement. The method’s efficiency is staggering, given the startup’s compact engineering team completed the entire development cycle in approximately 75 days. “This isn’t about brute-force parameter scaling,” the technical documentation explains. “It’s about mechanics that allow intelligence to emerge organically through cycles of exploration and integration.”
The framework operates in two phases:
- Amplification, which leverages additional computational power to generate solutions and capabilities reminiscent of next-level reasoning, and
- Distillation, where those elevated skills become internalized into the model’s core parameters.
This dual-phase loop bypasses the traditional hierarchy of model supervision, enabling progress untethered from the intelligence thresholds of teacher models or human annotators. Early results suggest Deep Cogito’s 70B model outpaces Meta’s Llama 4, which is built on a 109B Mixture-of-Experts architecture, raising questions about the future economics of AI training.
Performance Benchmarks and Real-World Relevance
Theoretically, larger parameter counts should dominate—yet Deep Cogito’s IDA-tuned 70B model managed a 91.73% accuracy score on the MMLU benchmark in standard mode, besting Llama 3.3 70B by 6.4 percentage points. In reasoning mode, it snatched a 91.00% score, outclassing DeepSeek’s 70B R1 Distill version by 4.4 percentage points. The company released data for its 14B model as a mid-sized proofpoint, showing consistent leads in reasoning and language proficiency:
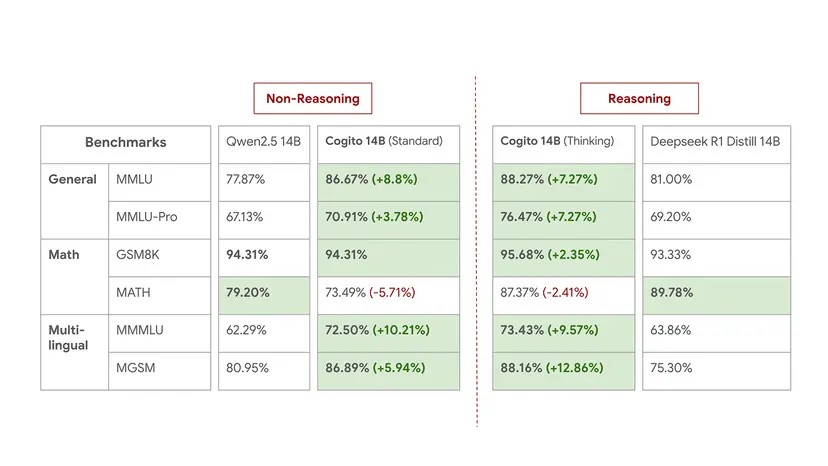

However, the startup tempers expectations by calling the launch a “preview,” noting that real-world performance diverges from benchmark results. CEO Aman Islam hinted at expanded product lines, with Mixture-of-Experts (MoE) architectures in 109B, 400B, and 671B parameter scales slated for release in coming months—all under open-source licenses intended to democratize access in a sector increasingly fractured by proprietary walls.
The announcement arrives during a period of intense scrutiny over AI’s trajectory. By leveraging a training technique that minimizes reliance on human input, Deep Cogito may offer a blueprint for resource-conscious development, appealing to companies and developers seeking to balance capability with cost. It also injects a fresh technical debate into the trend: Can recurrent distillation trump sheer scale in the race to AGI?
As investment dollars pour into the LLM arms race, the startup’s bold bet on self-amplifying intelligence—and its commitment to open access—could disrupt more bets on rigid, closed systems. For now, the skepticism as well as the wonder found in the tech community is reserved for the test labs and legal review teams shaping AI’s next chapter.
(Photo by Pietro Mattia)
Original article, Author: Samuel Thompson. If you wish to reprint this article, please indicate the source:https://aicnbc.com/279.html