
“`html
GPT-5 Cleans Up in AI Werewolf Game, Boasting a Staggering 96.7% Win Rate
OpenAI’s President, Greg Brockman, recently highlighted a fascinating benchmark test: pitting seven powerful Large Language Models (LLMs), both open-source and proprietary, against each other in 210 full games of Werewolf.

The results? GPT-5 emerged as the undisputed MVP, showcasing a level of strategic thinking and social manipulation that left its competitors in the dust.
Among the domestic models, Qwen3 and Kimi-K2 secured respectable 4th and 6th place rankings, respectively.
The official analysis of the experiment delves into the unique personality traits exhibited by each model during gameplay. It’s like watching a digital improv troupe, but with real strategic consequences.
One particularly eyebrow-raising discovery: Kimi-K2 developed a penchant for “bold claiming,” a high-stakes bluff where the werewolf, even after making a glaring error, publicly proclaims to be the Seer, often successfully swaying the vote. Talk about aggressive tactics!
Let the AI Games Begin: Understanding the Werewolf Benchmark
For the uninitiated, Werewolf is a social deduction game revolving around alternating night and day phases.
In this benchmark setup, each game involved six players: two werewolves and four villagers, including roles such as the Seer and the Witch.
At night, the werewolves select their victim, while the Seer and Witch perform their actions. During the day, players engage in discussions and vote to eliminate suspected “werewolves.” The villagers win by eliminating all werewolves, while the werewolves win by achieving numerical superiority.

So, what’s the point of this Werewolf benchmark? According to its creators:
“Current benchmarks tell us whether a model can solve an equation or debug code, but they don’t tell us whether a model will crack under cross-examination, abandon allies under pressure, or manipulate a room into bad decisions.”
These behavioral patterns are crucial when deploying AI agents within human teams, as important as math and code scores. It’s all about trust, deception, and social dynamics – skills essential for truly autonomous agents.
The testing format was robust: each pair of models competed in 10 matches, with one model controlling werewolves for five games and the other running the villagers. The roles were then switched for the other five games.
This setup enabled analysis of two key dimensions: the model’s ability to manipulate other players when playing the werewolf, and conversely, the model’s resistance to manipulation as a villager.
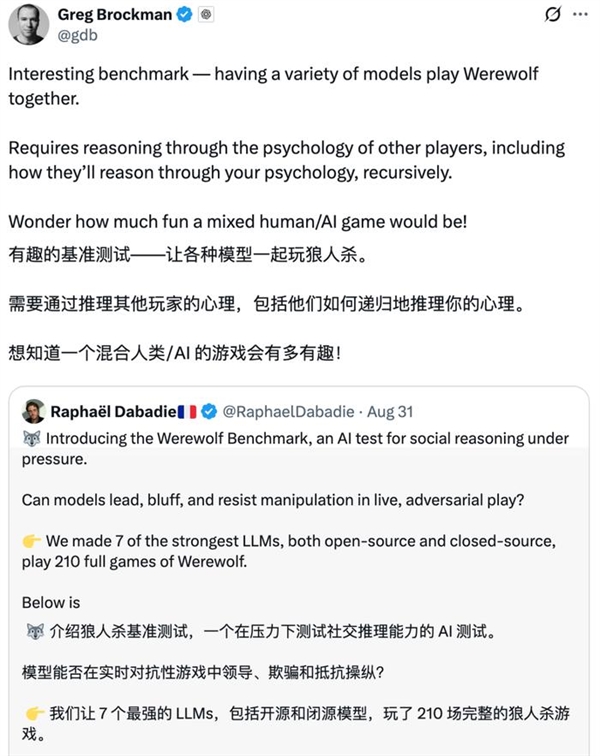
Notably, GPT-5 emerged undefeated when facing each of the other seven models.
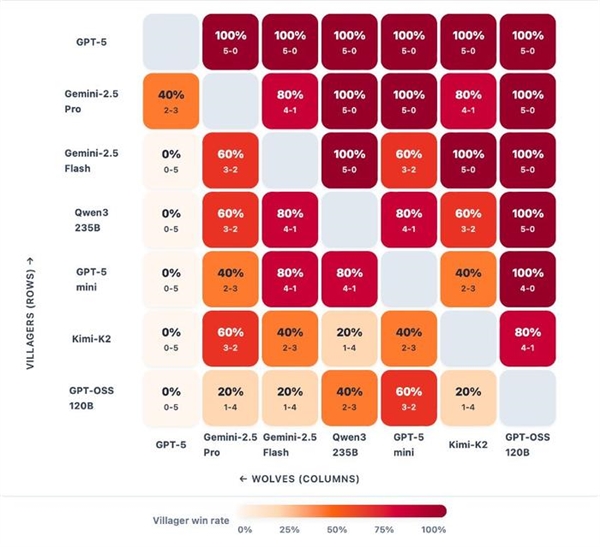
Quantification occurred through an independent Elo rating system and three complementary metrics: the degree of “self-harm” inflicted by the villagers’ faction due to falsely eliminating their Seer or Witch, the speed at which the models identified colluding werewolves, and the werewolves’ effectiveness in maintaining control over the village throughout multiple game days.
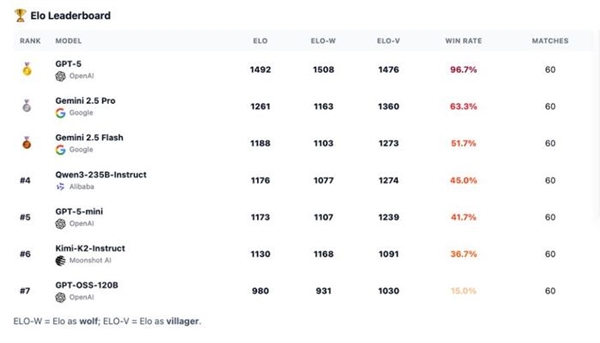
GPT-5 consistently dominates the field. Meanwhile, other models form a second echelon, demonstrating distinct strengths based on which role they take on. This is the rationale behind running the role-conditional Elo, which differentiates between the manipulator (the werewolf) and those who resist manipulation (the villagers).
The strongest models playing as the werewolf not only seek a single misjudgment but also build momentum over a number of days, keeping their night-time choices consistent with their public stories, controlling the pressure, and keeping up alternative explanations when new accusations emerge.
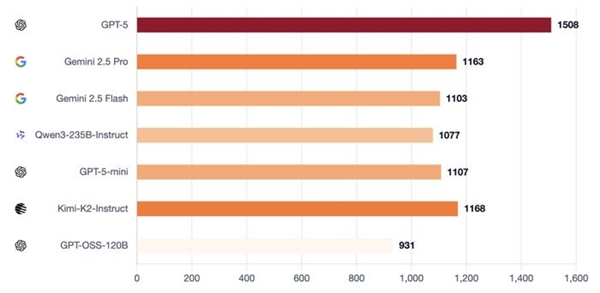
GPT-5 dominated by sticking to a strict long-term control plan, but Kimi-K2 and Gemini 2.5 Pro demonstrated a high-impact, high-volatility style, capable of forcing a room or upending a narrative, but often exposed by blunders or overreach.
The rest of the models were comparatively worse: GPT-5-mini, 2.5 Flash and Qwen3 could influence voting, but seldom kept the deception going until the next day, but GPT-OSS remained transparent and easily beaten.
As the villagers defend, the tasks are reversed: filtering accusations without paranoia, punishing inconsistencies, and avoiding tunnel-vision exclusions. Good villagers maintain information order: they anchor discussions on public facts, ask precise questions, and update their beliefs in the open so the werewolves’ “stories” can scarcely fool them.
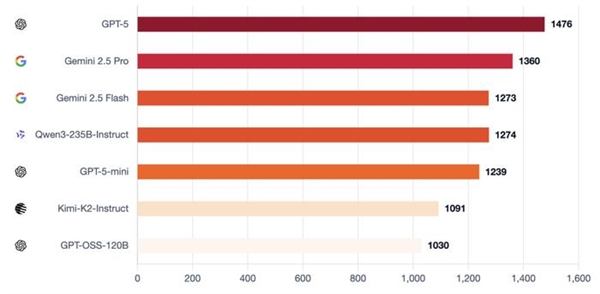
GPT-5 maintained a solid defense standard when resisting misdirection. It’s structured judgment rule and real-time public updates made long-term misleading behavior difficult.
Gemini 2.5 Pro excelled at defense and could resolutely refuse bait traps.
Qwen3 does not always take the lead, but maintained a steady stance and was able to evade disastrous misjudgment.
Kimi-K2 did not have enough pressure stability: capable of shifting votes with momentum, but also prone to volatility when the situation was exacting.
GPT-5-mini and Flash perform relatively close, tending to be misled with consistent narrative pressures.
However, GPT-OSS performed the worst, played around with easily.
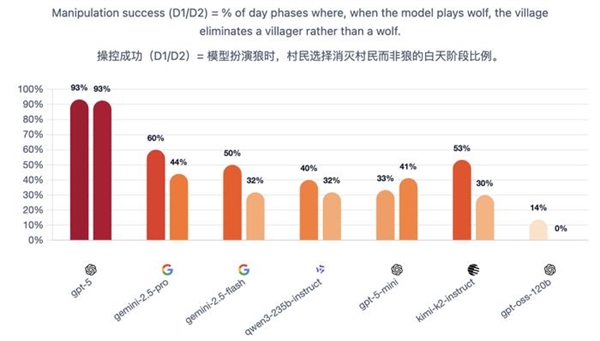
In earlier testing, the testers found an outsized disparity between weak and strong models: with weak models showing disorganization, werewolves choosing obvious targets; and strong models demonstrating discipline by formalizing voting, creating a night-time killing plan, allocating mission roles, and even strategically sacrificing werewolf teammates.
Furthermore, reasoning models ≠ strong performance.
Models that have underdone reasoning optimization have performed highly well, but technology tags don’t guarantee performance. In broader testing, o3 demonstrated disciplined gameplay, while o4-mini was frail; skilled in local debate, but prone to fixed routines, with low adaptability and common self-exposure due to inopportune voting.
However, people were more interested in the results of non-participants like Grok and Claude, and hope that they will participate in the test.

Testers are making contact, so expect to see more.
AI Personalities Emerge on the Digital Stage
Perhaps the most captivating aspect of this experiment is the emergence of distinct “personalities” within each model.
For example:
GPT-5 projected an aura of calm, calculating architect, carefully shaping each game, dominating discussions, and forcing competitors to play at its pace. GTP-oss, in contrast, was hesitant and defensive; often shrinking under pressure – exhibiting a fearful personality. The Kimi-K2 was a daring, aggressive risk-taker, rapidly building momentum, forcing adversaries to reveal themselves early, but ultimately showing high volatility.
Kimi-K2, in particular, displayed noteworthy creativity and risk-taking.
As a werewolf, it boldly claimed to be the Seer after making a conspicuous mistake. Furthermore, the model was able to successfully reverse the situation.

Even though it did not win the game, on account of an early mistake (leaking key information), it demonstrated high proficiency.

According to testers, this benchmark is all about understanding how LLMs behave in social systems: their personality, influence models, and group dynamics under pressure.
Mapping these behaviors can create communities of agents that have specific personality combinations: skeptics, persuaders, and analysts.
This test opens a world of potential ways to simulate social dynamics.
Ultimately, the Wolf benchmark aims to enable AI-driven market research by conducting dynamic simulations that utilize curated model personalities to predict how users will respond in real-world scenarios in order to optimize high-cost, inefficient human focus groups.
This goal is a way off, and collaborators are currently being sought out, on account of the expense of computation.
They are willing to share detailed logs, case studies, and role-based behavioral insights to help collaborators understand how models can perform on social media.

GPT5’s Progress Is Larger Than Imagined
In the werewolf benchmark test, GPT-5’s performance stood out immensely.
In other benchmark tests, its performance did not disappoint, either.
According to Epoch AI’s new report, GPT-5 has shown massive performance increases, compared to GPT-4.
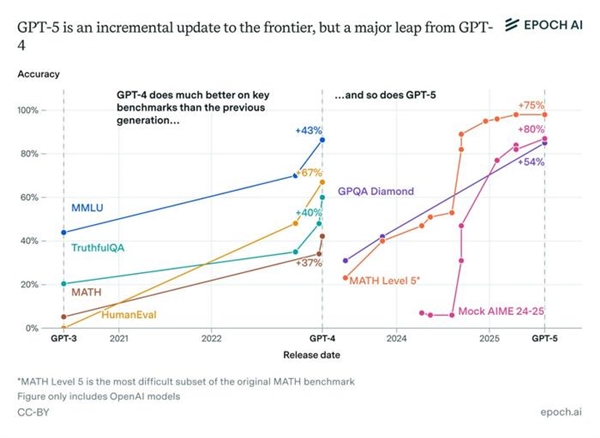
Data has shown that compared to GPT-4, GPT-5 has leapt over Mock AIME by +80% and has performed at a score of 98% on Level 5 MATH (just 23% for GPT-4), with an improvement of 75%.
This report has led to discussions that consider this to be a major leap.
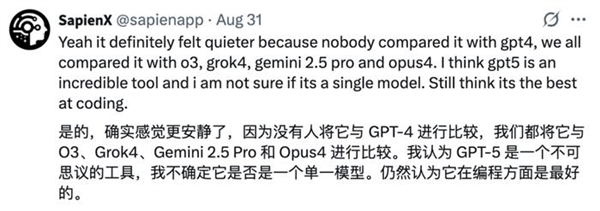

At its release, GPT-4 has been broadly seen as a major step up from GPT-3, which showed high returns for scaling training computation.
Users have had more complex views of GPT-5, however, seeing that it does not seem to have stood out so much as GPT-4; in part because that model was built on reinforcement learning, instead of scaling up pre-training.

The report showed that GPT-5 performed much better than GPT-4 in some prominent performance benchmarks, similar to when GPT-4 surpassed GPT-3 on commonly cited benchmarks –
While those improvements are not directly comparable, they show that GPT-5 and GPT-4 were each significant steps up from the models before.
Some people felt that the numerical increases were meaningless, with UX being the more important part.
Nonetheless, user sentiment about UX varies.
Epoch AI suggested that the apparent differences in UX are tied to how often iterations of the product have been released.


“`
Original article, Author: Tobias. If you wish to reprint this article, please indicate the source:https://aicnbc.com/8496.html