
Here’s the rewritten article, adhering to your guidelines:
In a stunning revelation, Stanford researchers have stumbled upon something truly remarkable: AI-generated CUDA kernels that outperform even the most meticulously optimized versions crafted by human experts. This unexpected breakthrough could redefine the landscape of deep learning, leaving the tech world buzzing.
Stanford’s recent findings are nothing short of impressive. Their AI-optimized kernels demonstrated a significant performance boost across various deep learning operations, even exceeding the capabilities of native PyTorch by a substantial margin. The results speak for themselves:
* Matrix Multiplication (Matmul, FP32): Achieved 101.3% performance compared to PyTorch’s torch.matmul.
* 2D Convolution (Conv2D): Reached 179.9% of torch.nn.Conv2D’s performance.
* Softmax: Demonstrated 111.8% of torch.softmax’s efficiency.
* Layer Normalization (LayerNorm): Soared to 484.4% of torch.nn.LayerNorm’s capabilities.
* Conv2D+ReLU+MaxPool Combos: Outperformed PyTorch reference implementations by 290.1% and torch.compile() by 189.0%.
_(Performance percentages were benchmarked on an NVIDIA L40S GPU and are defined as the reference time divided by the generated kernel time.)_


The truly astonishing aspect? This remarkable achievement was, in the researchers’ own words, an “accident.” They initially set out to generate synthetic data to train a kernel generation model. The team found that the synthetic data, when tested, could alone be used to develop incredibly high-performing kernels.
The news has sparked a flurry of excitement among industry watchers. The question on everyone’s mind: Is this the dawn of AI replacing kernel engineers?
Beyond the impressive performance gains, what sets this research apart is the novel methodology employed by the Stanford team.
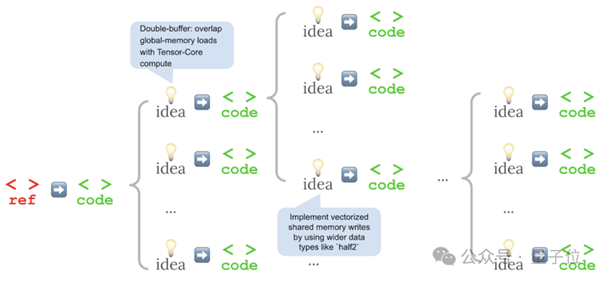
Rather than relying on a straightforward, iterative optimization process (akin to a hill-climbing algorithm), the researchers incorporated a language reasoning step between each iteration. This strategically encouraged diverse exploration within the search space.
In essence, the system “thought” about how to improve with each refinement, sparking new ideas and leading to superior solutions.

Here’s a closer look at how they achieved this….
**From Natural Language to Code: The Optimization Approach**
As described in the team’s blog, the concept behind their kernel generation is elegantly simple: Given a PyTorch (torch) code snippet, the system is tasked with writing custom kernels to replace the original operators.
These kernels are written in pure CUDA-C, negating the need for specialized libraries and DSLs (Domain-Specific Languages) like CUTLASS and Triton. What distinguishes this approach from traditional methods is the use of natural language to generate optimization ideas first. These ideas are then translated into new code variants.
The team reasoned that a “sequential modification” strategy would lack diversity, leading to the risk of getting stuck in local minima, revisiting the same transformations, or endlessly optimizing fruitless paths.
To amplify the diversity of ideas, the Stanford team then embraced a multi-branch exploration model. Rather than refining only a single candidate at each step, they broadened the approach by letting each idea spawn multiple implementations, with the highest-performing kernel serving as the launchpad for the next round of refinement.
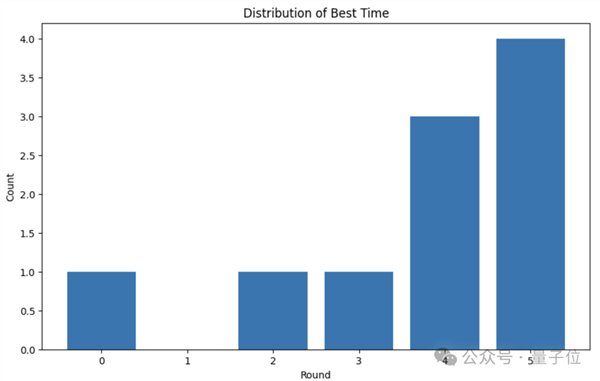
The team used OpenAI’s o3 and Gemini 2.5 Pro to tackle ten problems from Level 1 of the KernelBench benchmark, and after multiple rounds, the top kernels emerged. Most of the best results materialized in later iterations (across 5 rounds), often rounds 4 or 5.
KernelBench, an internal standard developed by the Stanford team, sets the standard for AI-generated kernel testing. This benchmark is organized across three levels, with Level 1 encompassing single primitive operations, which form the foundation of AI, including convolutions, matrix-vector/matrix-matrix multiplication, loss functions, activation functions, and layer normalization.
This latest discovery, alongside breakthroughs like DeepMind’s AlphaEvolve and the discovery of a Linux 0-day vulnerability in o3, has led some observers to suggest that Gemini 2.5 Pro and o3 have reached a new level of sophistication.
Returning to the Stanford project, the process of generating the CUDA kernels reveals that the model’s approach is beginning to reflect the intuition of human experts:
* **Memory Access Optimization:** Enhancing the efficiency of data movement across various memory hierarchies (global memory, shared memory, and registers) and ensuring data access maximizes bandwidth while minimizing conflicts.
* **Asynchronous Operations and Latency Hiding:** By overlapping slower operations (such as accessing global memory) with calculations or other memory transfers, the system “hides” the latency of those slower operations.
* **Data Type and Precision Optimization:** Leveraging lower-precision data types (e.g., FP16 or BF16) to reduce memory bandwidth requirements and improve caching efficiency.
* **Compute and Instruction Optimization:** Boosting the efficiency of arithmetic calculations themselves by reducing the number of instructions or deploying specialized hardware instructions.
* **Parallelism and Occupancy Enhancement:** Maximizing the number of active threads on streaming multiprocessors (SMs) to better hide latency and improve overall throughput.
* **Control Flow and Loop Optimization:** Reducing the overhead associated with loops, branching, and index calculations.
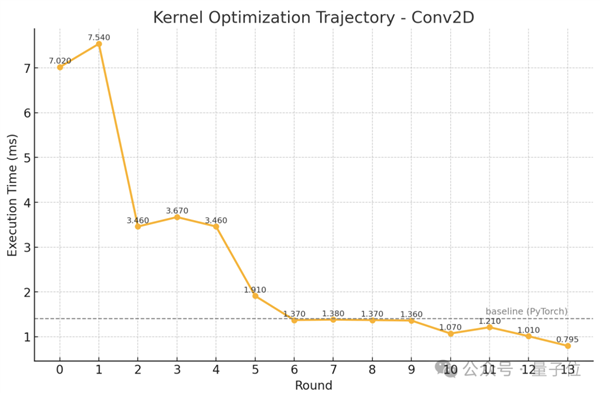
The Stanford team also presented a detailed collection of optimization paths. This revealed that not every optimization step necessarily speeds up the process; however, through combining multiple steps, kernel efficiency could be significantly enhanced, ultimately surpassing PyTorch.
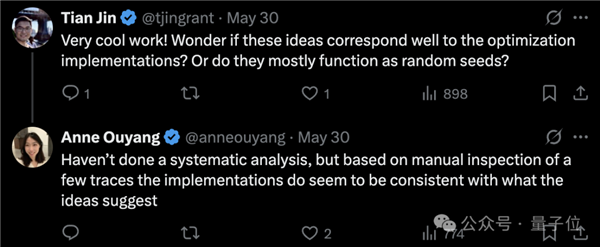
Regarding the practical implementation, researchers were asked if the optimization suggestions for AI-generated CUDA kernels could be translated into corresponding code implementations or were simply triggering random exploration.
The authors stated that despite a lack of rigorous system verifications at the time, the generated CUDA implementations matched the proffered optimization suggestions across the manually inspected cases.
In other words, the AI wasn’t simply optimizing with chance, but it was indeed endeavoring to realize its own proposed strategies.
**The Team Behind the Breakthrough**
This groundbreaking research was spearheaded by a trio of brilliant minds: Anne Ouyang, Azalia Mirhoseini, and Percy Liang.
Dr. Ouyang, currently a doctoral candidate at Stanford’s SAIL (Stanford AI Lab), earned her Bachelor’s and Master’s degrees from MIT. She previously worked with the cuDNN team at NVIDIA.

Professor Percy Liang is an Associate Professor of Computer Science and an Assistant Professor of Statistics at Stanford University. Dr. Liang, who directs the Stanford Center for Research on Foundation Models, has been involved in collaborative research, as well as research advances with Fei-Fei Li.

Dr. Azalia Mirhoseini is an Assistant Professor of Computer Science and the founder of the Stanford Extend Lab. Her prior posts have included work with DeepMind, Google Brain, and Anthropic. Dr. Mirhoseini’s prior research includes MoE and the AlphaChip algorithm for chip design.

The researchers’ unexpected discovery came while seeking to create data to train kernel generation models.
The researchers found that the synthetic data, when used during testing, could produce high-performing kernels.
Because these kernels took advantage of advanced optimizations and hardware characteristics, thought until now to be complex, the team chose to publish their findings in a blog post, despite the methods to create data being unavailable for now.
Most importantly, these techniques have already demonstrated significant capability.
Additionally, the team viewed this discovery as resonant with recent trends, such as the belief that large-scale retraining may not always be necessary.
Careful searching and branching strategies, at times, are critical for opening the door to scientific innovation and tackling complex problems; broader gains are further assured by a verifier.
Combined with sturdy reasoning abilities and an emphasis on exploring all probable scenarios at once, the results look promising. Much the same could be said of DeepMind’s AlphaEvolve, AlphaEvolution, as well as that of Gemini 2.5 Pro itself.
The research team suggests there’s still plenty of room for improvement. The team is currently optimizing two dimensions:
* FP16 Matmul: 52% performance of torch.matmul
* FP16 Flash Attention: 9% performance of torch.nn.functional.scaled_dot_product_attention
Compared to FP16 and BF16, FP32 typically sees lower optimization on new hardware, which is why achieving performance gains is easier for FP32 kernels versus PyTorch.
The team believes that while limitations remain, the future looks bright. At the outset, they couldn’t generate a functional kernel, but through relentless refinement of their search methodologies, they’ve elevated the performance of flash attention to noteworthy levels.
Notably, the entire search operation only consumed a modest 3 million tokens for input and 4 million for output.
**One More Thing**
In an interesting aside, Stanford isn’t the only group working on kernel large language models.
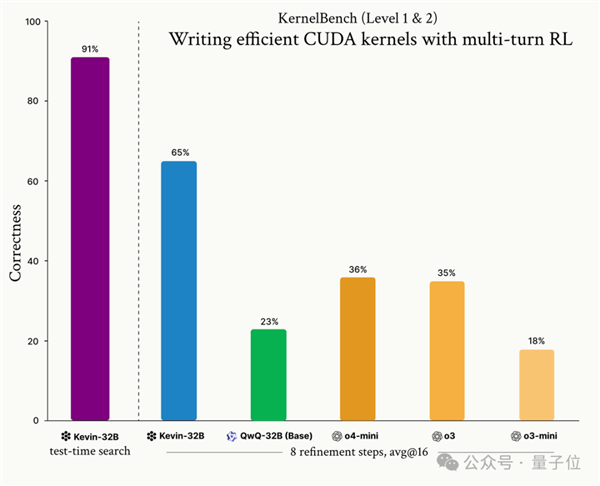
In May, Cognition, the developers of Devin, open-sourced Kevin-32B, the first large language model capable of writing CUDA kernels through reinforcement learning. This large language model leverages QwQ-32B on the KernelBench dataset, utilizing GRPO to achieve multiple reinforcement learning rounds, outperforming o3 and o4-mini.
[1]
[2]
[3]
Original article, Author: Tobias. If you wish to reprint this article, please indicate the source:https://aicnbc.com/1392.html